Reducing the Dimensionality of Data with Neural Networks 笔记
背景
Hinton在06年发表在Science,是深度学习爆发前的里程碑成果,展示了深度学习的广阔前景。
笔记
介绍
通过训练有多个小中间层的多层神经网络,将高维数据转换为低维编码,以此可以重建高维数据。用梯度下降法可以在这个自编码网络上微调参数,但需要初始权重较好。本文介绍了一种比PCA更好的初始权重的方法。
正文
提出了降维方法主成成分分析的非线性推广,自编码网络由编码器、解码器组成。用链式规则(反向传播)可以优化权重,但多隐层网络初始权重大导致局部极小值、初始权重小梯度消失导致不可训练。本文介绍了一种一次训练一层的预训练方法。
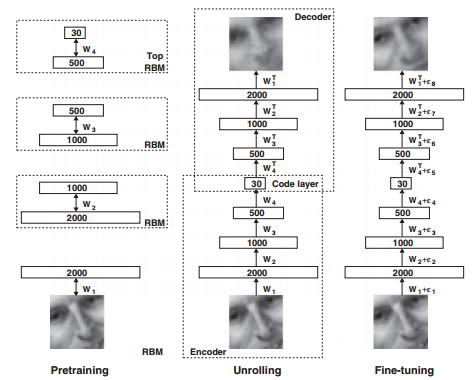
预训练是通过对比散度contrastive divergence,CD训练受限玻尔兹曼机RBM,这里不太熟悉暂时跳过,总之就是通过CD-1算法逐层训练。
预训练Pretrain之后是Unrolling过程,将encoder的W^T构造为decoder还原输入。之后Fine-tuning过程用SGD、BP微调参数。目标函数是交叉熵。
最后通过多个数据对比autoencoder与PCA效果。将输出特征降维成2维后,可以明显发现autoencoder的数据分布线性可分。
感悟
作者提出了深度网络降维的训练方法Pretrain、Unrolling、Fine-tuning。之后的一些实验证明,只靠Fine-tuning仍然可以得到较好的结果。Deep Learning Review里也提到了,局部极小值等问题并不严重。因此文中的具体训练方法现在可能不再适用,但autoencoder降维的思想可以启发我们的工作。
- 上一篇 Deep Learning Review 阅读笔记
- 下一篇 Imagenet classification with deep convolutional neural networks 笔记