Imagenet classification with deep convolutional neural networks 笔记
背景
论文展示了神经信息处理系统的进步,提出了AlexNet,是深度学习的突破性进展。
笔记
介绍
为了能对自然图像进行分类识别,需要有像CNNs一样的大容量模型,容量取决于深度和宽度。尽管CNNs高性能、高效率,但计算高分辨图片时仍消耗过大,本文提出了一种在ImageNet这种包含大量标签图片的数据集上训练出不过拟合的模型的方法。 突出贡献:
- 基于ILSVRC-2010和ILSVRC-2012的子集训练了一个最大的CNNs模型,是当时的最优结果。
- 实现了在GPU中进行卷积和其他CNNs操作。
- 网络中使用了一些不常见和新的特征来提升性能,减少训练时间。
- 采用了有效措施预防过拟合。
- 最终包含5层卷积层和三层全连接层。受限于GPU内存和训练时间。
正文
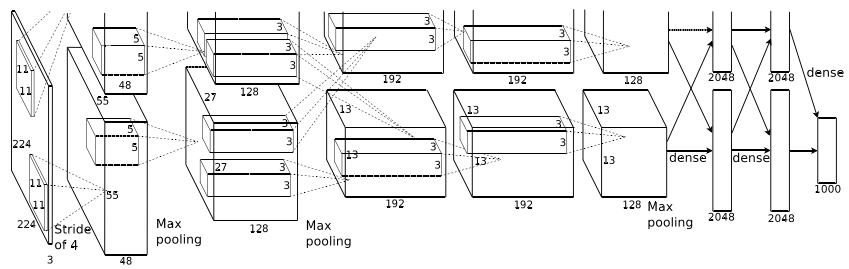
- 数据集
- 图片来源:ImageNet子集,ILSVRC比赛
- 图像预处理:大小变换,将短边缩小到256像素,裁出中央256*256像素。
- 结构
- 8层,5层卷积层,3层全连接网络,最后一层是softmx输出结果。
- 改进:
- 激活函数ReLU,训练更快。学习速度快。
- 多GPU训练,两个GPU可以互相读写。各一半神经元,某些层进行GPU通讯。
- 局部响应标准化。在相对的局位置上,类似动物神经元,在相邻有不同的卷积核之间进行相互的侧向抑制。
- 重叠采样。采样z*z个像素,移动距离为s。若s=z则是传统方法,s<z则重复采样,会略微减少过拟合。
- 降低过拟合
- 数据增强:
- 图像随机抽取224*224切片、水平翻转增加训练2048倍数据量。测试时用同样方式构造测试集,取结果平均值。
- 通过PCA的方法改变RGB通道强度。
- Dropout:
- 某些层50%概率输出0,不参加forward、backward。迫使神经元减少互相作用学习独立更多有用特征。
- 数据增强:
- 学习细节
- batch size 128
- 具有动量的小批量梯度下降。
- 在训练过程中,当网络的validation error 不再下降时,把学习速率缩小10倍。
- 结果
- Top1 Top5错误率最优。
- 性能评估
- 两个GPU上的卷积核对颜色敏感度不同。
- 主体不在中央也能分类成功,但指代不明的不易分类。
- 最后一个pooling层,两个图片特征向量欧氏距离越近,越相似。
感悟
当时CNN的难点似乎是深度导致的学习效率问题。个人认为对工业界来说结构改进带来的1~2%收益并不是很大。文中ReLU的应用、以及降低过拟的数据增强、dropout技巧值得学习。
- 上一篇 Reducing the Dimensionality of Data with Neural Networks 笔记
- 下一篇 Very deep convolutional networks for large-scale image recognition 笔记