Very deep convolutional networks for large-scale image recognition 笔记
背景
作者Simonyan,Karen和Andrew Zisserman。论文提出了VGGNet,神经网络变得非常有深度。 本文研究了深度对卷积网络在大规模图片识别中准确率的影响。对3*3卷积核深度增加到16、19层后,网络性能得到显著提升。
笔记
介绍
回顾CNN在大规模图像识别中的成功,为了提高准确率,业界做了各种各样的改进。本文关注了深度,因此固定其他参数,通过增加卷积层增加网络深度。本文提出的网络结构不但在比赛中取得了好成绩,在其他数据集表现也不错。
正文
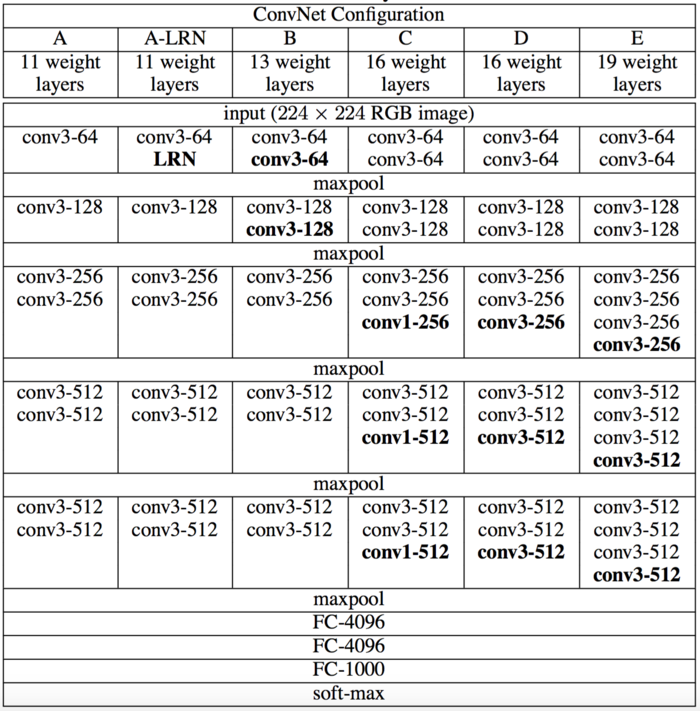
- 卷积层配置
- 卷积网络的通用结构
- 输入固定为224*224的图像,预处理,像素减去训练集RGB均值。
- 卷积核33(也有11卷积核),步长1像素。
- padding保持分辨率,3*3卷积核填充1像素。
- 5个池化层,2*2窗口maxpooling。
- 一堆卷积层之后是3层全链接层(4096-4096-1000),最后接softmax。
- 所有隐层用ReLU。
- 评估用的配置
- 讨论与比较
- 3*3卷积核的好处:无pooling堆叠后相当于更大receptive fields,优点1)决策函数更具判别性,2)减少了参数的数量。
- 1*1卷积核是为了增加非线性。
- 和其他网络做了对比。
- 卷积网络的通用结构
- 分类框架
- 训练
- 使用含动量的小批量mini-batch梯度下降优化多元逻辑回归来对模型进行训练。
- 前两个全连接层执行dropout对训练进行正则化。
- 验证集准确率稳定时将学习率除以10。学习率总共降低3次。
- 优点:1)更深的深度和更小的卷积核隐式的增强了正则化,2)某些层进行预训练,网络A用来初始化。
- 训练图片缩放到S后剪裁成224*224,随机水平翻转、RGB颜色转换。S可以固定,也可以随机、看作尺寸抖动。
- 测试
- 图片缩小到Q,不剪裁将网络应用到整个图像,得到的结果进行平均。同样水平反转图像。
- 不剪裁效率高,类似剪裁的原理,可以提高准确率。padding来自相邻图像,获得更多上下文信息。
- 实现细节
- Caffe + 多GPU
- 训练
- 分类实验
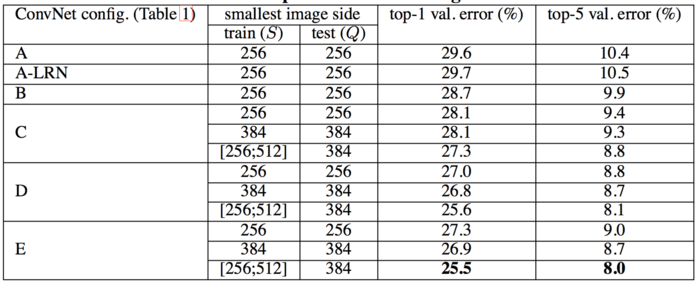
- 单一尺度评估Q=S
- 局部归一化对模型没有改善
- 分类误差随深度增加而减小,额外的非线性有帮助但可以直接用卷积核,小卷积核的深度网络优于大卷积核的浅层网络。
- 尺度抖动比固定最小边好,增强了捕获多尺度图片。
- 多尺度评估
- 尺度抖动会导致更好的性能。
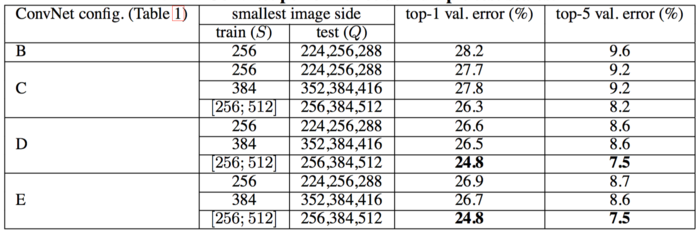
- 多裁剪评估
- 重裁切比密集评估的效果略好,组合效果最好。
- 卷积网络融合
- 计算多个模型soft-max的平均值,结合了几种模型的输出。由于模型的互补提高了性能。
- 与现有技术比较
- 明显优于上一代模型,没有偏离LeCun et al. (1989)的经典结构,而且大大提升了它的深度。
- 单一尺度评估Q=S
- 结论
- 深度有益于分类准确度。
感悟
本文通过实验验证了深度对分类准确度的影响,可见在经典结构的基础上,通过提升深度可以带来了巨大效果提升。